

Build Self-Learning Agents With No Fine-Tuning on AWS
How to architect a production-grade AI agent that improves at runtime — using Amazon Bedrock, Lambda, DynamoDB, Step Functions, and a feedback loop that writes new knowledge back into the Knowledge Base after every interaction. Zero GPU training required.
TL;DR — What You'll Build
- Runtime learning loop — agent extracts
[LEARNING]:tags from its own responses and writes them back to Bedrock Knowledge Base automatically - 5-layer modular architecture — Ingestion → Orchestration → Agent Core (ReAct) → Memory → Feedback, wired by Step Functions
- No fine-tuning, no training data — the base model never changes; only context improves with each interaction
- Full Terraform — 7 independent modules,
terraform applyin ~15 minutes - Deploy time: ~15 min · First interaction: ~2s · Learning propagation: ~2 min
Table of Contents
- Why Not Fine-Tune?
- 5-Layer AWS Architecture
- Ingestion Layer — API Gateway, EventBridge, SQS
- Dispatcher & Step Functions Orchestration
- Context Builder — Episodic & Semantic Memory
- Reasoning Engine — ReAct Loop with Bedrock
- Feedback Loop — Evaluator & Knowledge Updater
- Modular Terraform Infrastructure
- Testing the Agent
- Cost & Observability
- Conclusion
1. Why Not Fine-Tune?
Fine-tuning a large language model changes its weights permanently. It requires a labelled dataset, significant GPU compute, a model registry, and a deployment pipeline that can take days to iterate. For most production use cases, the agent doesn't need new weights — it needs better context at inference time.
The core insight behind this architecture is simple:
Intelligence at runtime = Base Model + Right Context + Feedback Loop
Instead of changing what the model knows (fine-tuning weights), we change what it sees (dynamic context assembled from two memory types) and what it remembers (episodic turns in DynamoDB + semantic facts in Bedrock Knowledge Base). The agent gets smarter with every interaction — without a single training run.
This approach maps directly onto three managed AWS services that cover the hardest parts: Amazon Bedrock for serverless LLM inference with built-in Knowledge Bases, DynamoDB for sub-millisecond episodic memory with TTL auto-expiry, and Step Functions for durable orchestration of the multi-step reasoning loop.
| Fine-Tuning | This Architecture (Runtime Learning) | |
|---|---|---|
| Time to update | Days / weeks | ~2 minutes |
| Training data required | Labelled dataset | None |
| Cost | $$$–$$$$ | $ per token |
| Reversible | No (new model version) | Yes (edit KB document) |
| Domain adaptation | Baked into weights | Injected at runtime |
| Infrastructure required | GPU cluster + model registry | Lambda + DynamoDB + S3 |
2. 5-Layer AWS Architecture
The system is organised into five loosely coupled layers. Each layer is one or more Lambda functions; the layers communicate through Step Functions state machine transitions.
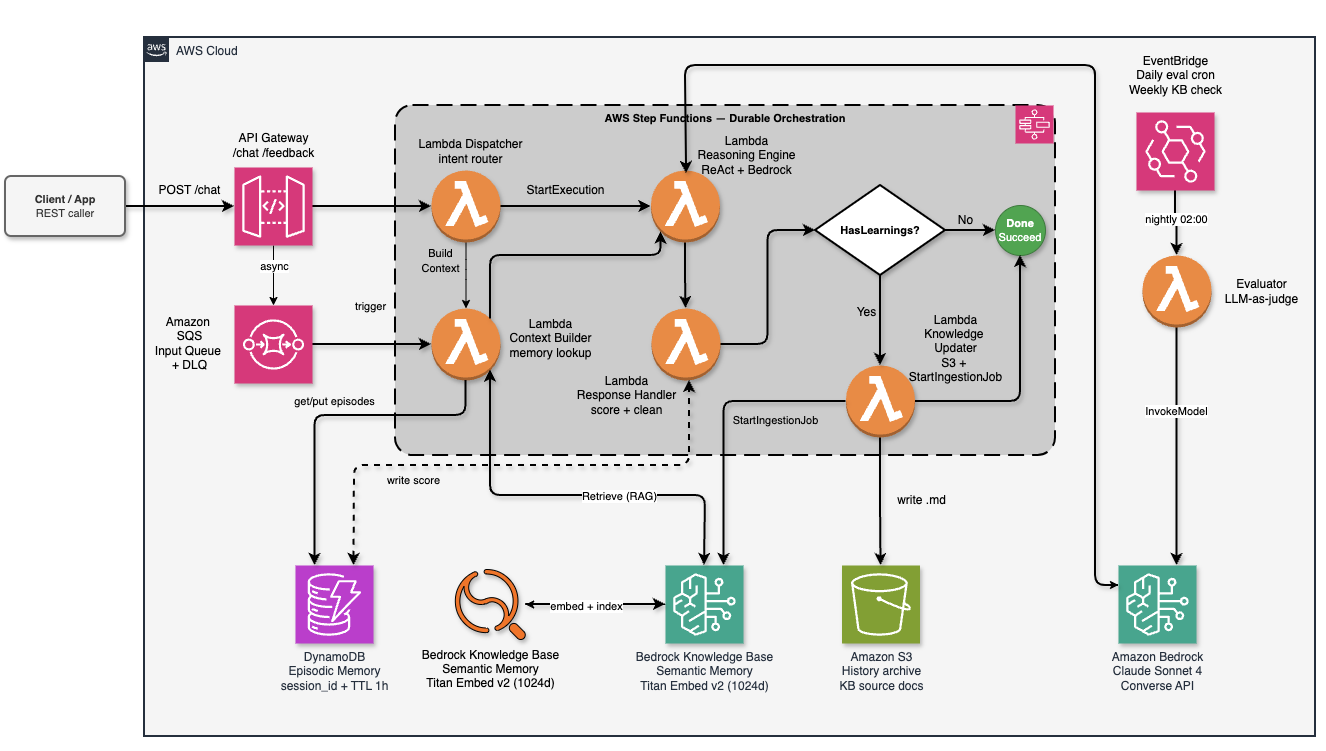
Figure 1 — Complete AWS service architecture: Client → API Gateway → SQS → Dispatcher Lambda → Step Functions orchestrates Context Builder, Reasoning Engine (Bedrock Converse API / ReAct), Response Handler → HasLearnings? Choice → Knowledge Updater (S3 + StartIngestionJob) → Done. DynamoDB provides sub-millisecond episodic memory; OpenSearch Serverless backs the Bedrock vector Knowledge Base. Every service deployed via 7 independent Terraform modules.
The critical path for a typical interaction is: Dispatcher → BuildContext → ReasoningEngine → HandleResponse → (UpdateKnowledge if learnings exist) → Done. The Step Functions state machine handles retries, error routing, and the conditional branch to knowledge update — so individual Lambdas stay stateless and focused on a single concern.
3. Ingestion Layer — API Gateway, EventBridge, SQS
The agent accepts input from three surfaces: synchronous (API Gateway REST), event-driven (EventBridge), and asynchronous (SQS queue). Using SQS as a buffer decouples spiky load from the reasoning pipeline, which is critical for keeping Lambda concurrency costs predictable.
POST /chat → API Gateway → Lambda Dispatcher → Step Functions
Scheduled → EventBridge → Lambda Dispatcher → Step Functions
Batch data → SQS Queue → Lambda Dispatcher → Step FunctionsEach surface serialises the request into a canonical AgentEvent shape before passing it to the Dispatcher. The SQS queue has a Dead Letter Queue (DLQ) configured with maxReceiveCount: 3 — failed messages surface in CloudWatch Alarms rather than silently disappearing.
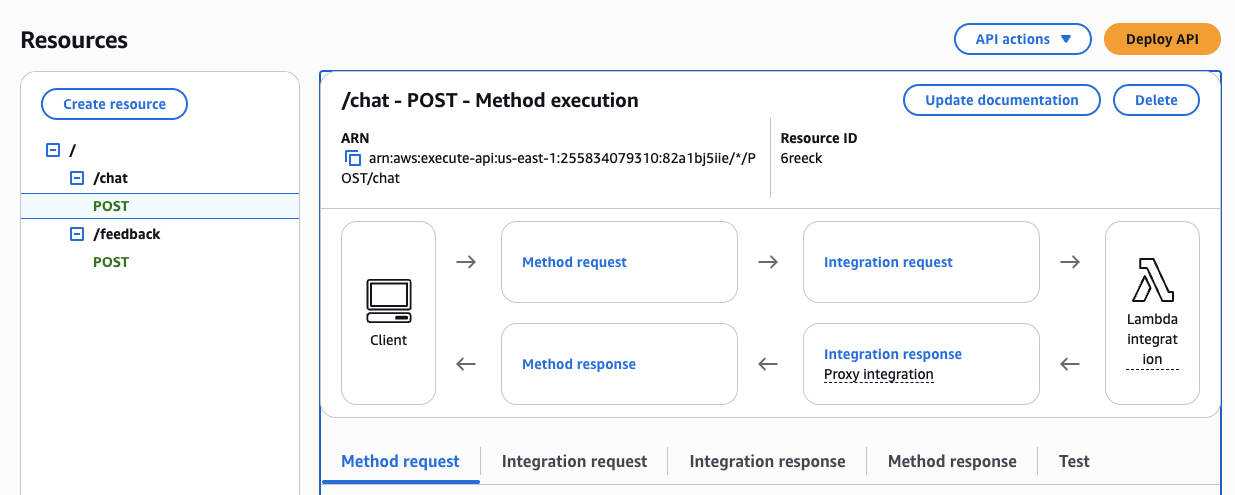
Figure 2 — AWS Console: /chat POST method execution in API Gateway. The Lambda proxy integration passes the full request body to the Dispatcher without transformation. ARN: arn:aws:execute-api:us-east-1:255834079310:82a1bj5Iie/*/POST/chat. Both /chat and /feedback endpoints point to the same Dispatcher Lambda, which differentiates intent after parsing the payload.
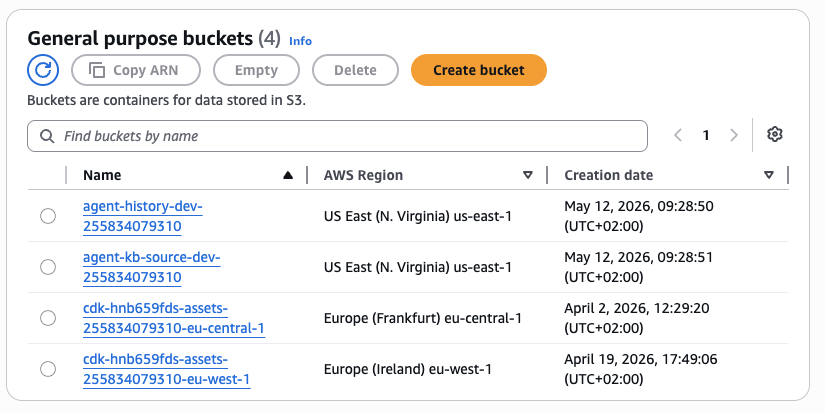
Figure 3 — The two S3 buckets provisioned by the storage Terraform module: agent-history-dev-255834079310 (raw interaction archive, Glacier lifecycle after 90 days) and agent-kb-source-dev-255834079310 (Knowledge Base source documents). Both appeared in us-east-1 within 60 seconds of terraform apply completing on May 12, 2026.
4. Dispatcher & Step Functions Orchestration
The Dispatcher Lambda does two things: classifies user intent with a zero-shot Bedrock call, then starts a Step Functions execution. Using Step Functions as the orchestrator — rather than a monolithic Lambda — gives the system durability, built-in retries with exponential backoff, and a visual execution graph in the AWS Console.
def _classify_intent(text: str) -> str:
prompt = f"""Classify the following user message into ONE of these intents:
[question, task, feedback, clarification, chitchat]
Message: {text}
Reply with ONLY the intent label, nothing else."""
response = _invoke_bedrock(prompt, max_tokens=10)
return response.strip().lower()The state machine definition is intentionally simple — five states with clear error handling:
BuildContext → RunReasoningEngine → HandleResponse → HasLearnings?
├─ true → UpdateKnowledge → Done
└─ false → Done
(any state) → HandleError → FailThe HasLearnings Choice state means knowledge ingestion only runs when the Reasoning Engine actually extracted new information from the interaction. This keeps latency down for routine queries and avoids unnecessary Bedrock KB ingestion jobs.
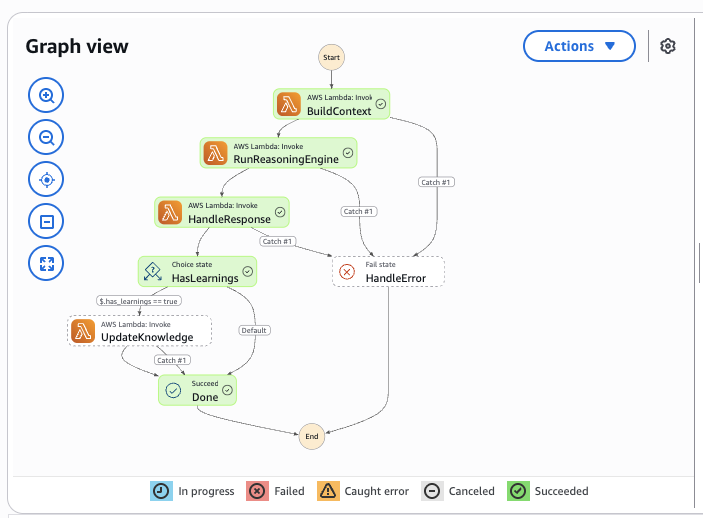
Figure 4 — AWS Step Functions Console: real Graph view of the self-learning-agent-dev state machine. The green checkmarks show a successful execution: BuildContext → RunReasoningEngine → HandleResponse → HasLearnings? (Choice state) → UpdateKnowledge (branch taken when $.has_learnings == true) → Done. The HandleError Fail state (red ✕) catches exceptions thrown by any step. All retry policies with exponential backoff are defined in the Terraform stepfunctions module.
5. Context Builder — Episodic & Semantic Memory
Before calling the LLM, the Context Builder assembles context from two memory types. This is the architectural equivalent of a human checking their notes and searching their memory before answering a question.
Short-Term (Episodic) Memory — DynamoDB
Each conversation turn is stored in DynamoDB with session_id + timestamp as composite key and a ttl attribute for automatic expiry — no cron job needed. The last N turns are fetched with a Query and ScanIndexForward=False:
def _get_short_term_memory(session_id: str, limit: int = 10) -> list[dict]:
resp = memory_table.query(
KeyConditionExpression="session_id = :sid",
ExpressionAttributeValues={":sid": session_id},
ScanIndexForward=False,
Limit=limit,
)
return list(reversed(resp.get("Items", [])))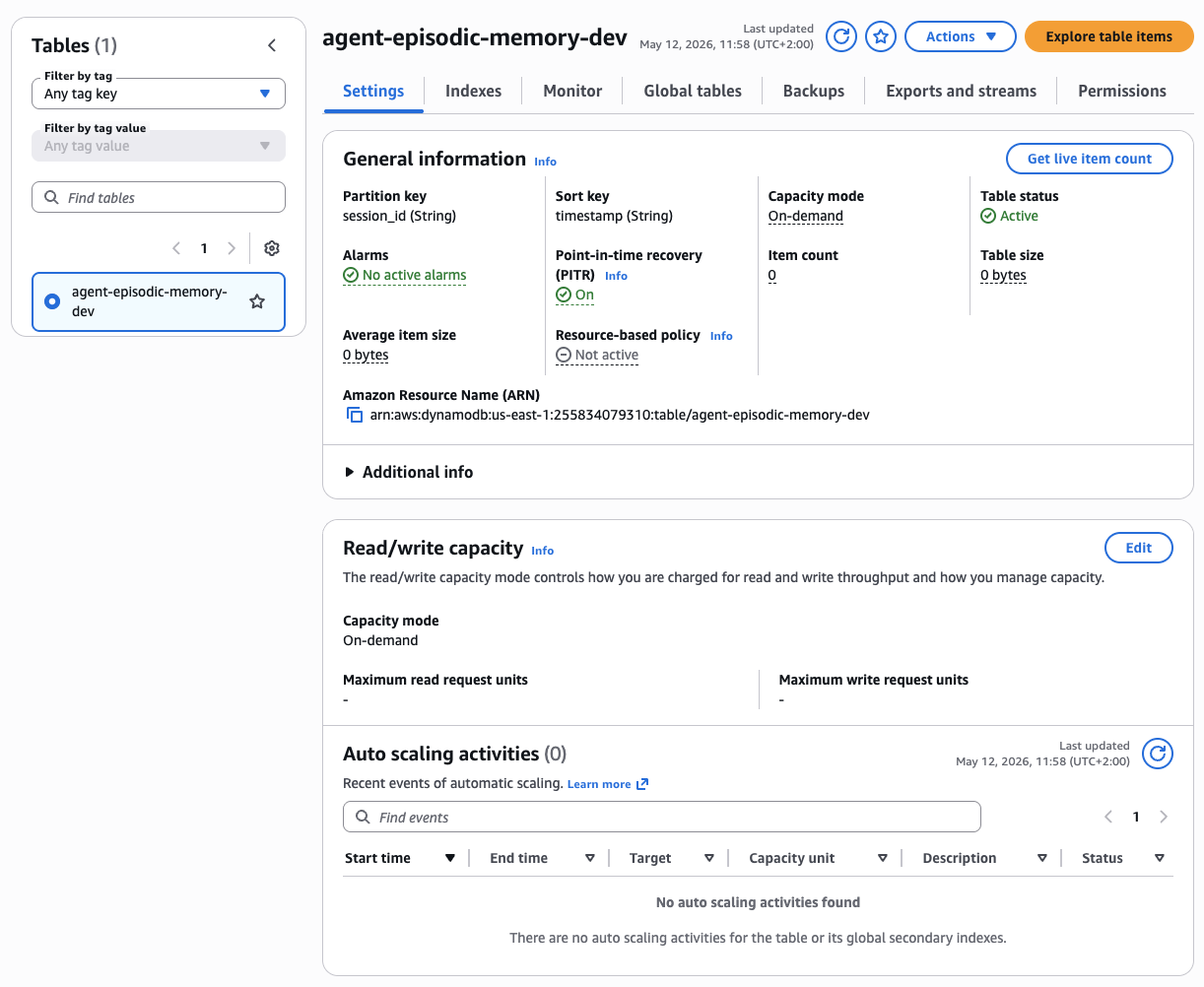
Figure 6 — DynamoDB table agent-episodic-memory-dev in AWS Console: partition key session_id (String) + sort key timestamp (String), On-demand capacity mode, PITR enabled. ARN: arn:aws:dynamodb:us-east-1:255834079310:table/agent-episodic-memory-dev. Item count shows 0 at creation — the table grows with each conversation and auto-expires records after 1 hour via TTL.
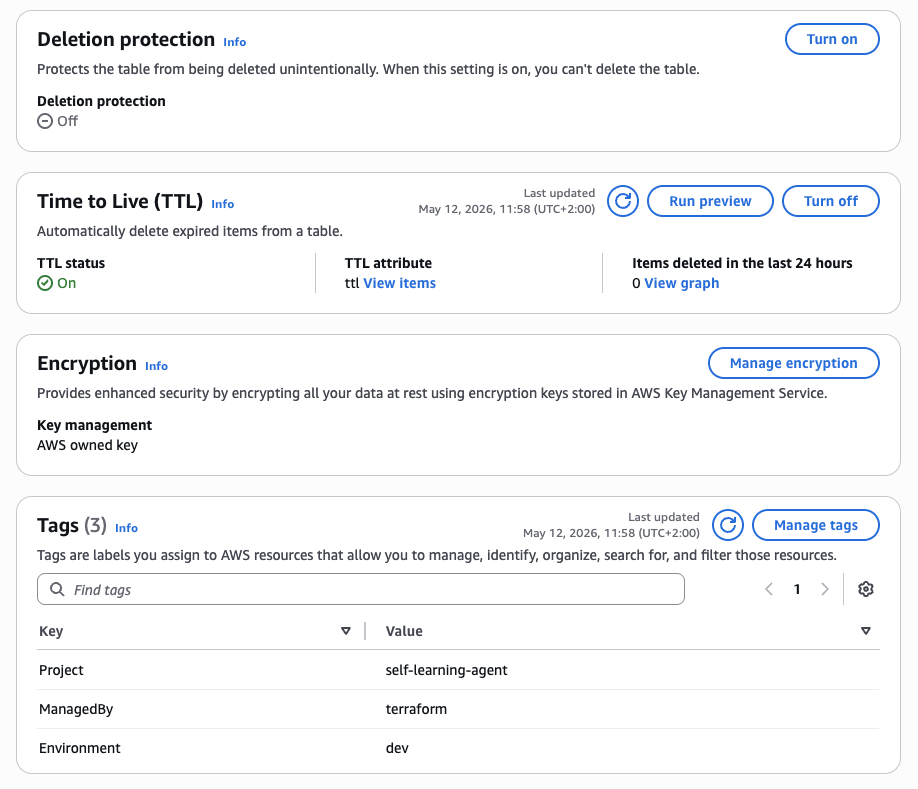
Figure 7 — DynamoDB TTL configuration: attribute ttl, status On. DynamoDB automatically deletes expired items without any maintenance Lambda or cron job. Encryption uses AWS owned keys. Resource tags confirm Terraform management: Project=self-learning-agent, ManagedBy=terraform, Environment=dev.
Semantic Memory — Bedrock Knowledge Base (RAG)
The Bedrock Knowledge Base backs the agent's long-term factual memory. It embeds documents using Amazon Titan Embeddings v2, stores vectors in OpenSearch Serverless, and retrieves them at query time with cosine similarity search. Retrieved chunks are injected into the prompt inside <semantic_memory> tags:
resp = bedrock_agent.retrieve(
knowledgeBaseId=KB_ID,
retrievalQuery={"text": query},
retrievalConfiguration={
"vectorSearchConfiguration": {"numberOfResults": 5}
},
)
# Inject top-5 chunks tagged with source URI and relevance score
chunks = "\n\n".join(
f"[Source: {c['source']} | score: {c['score']:.2f}]\n{c['content']}"
for c in retrieved
)
context_message = f"<semantic_memory>\n{chunks}\n</semantic_memory>\n\n{user_input}"The explicit <semantic_memory> tags serve a deliberate purpose: they tell the model exactly where its retrieved knowledge ends and the user's question begins, which measurably reduces hallucination on boundary-crossing queries. They also make it easy to strip the tags out in post-processing when checking what context was used.
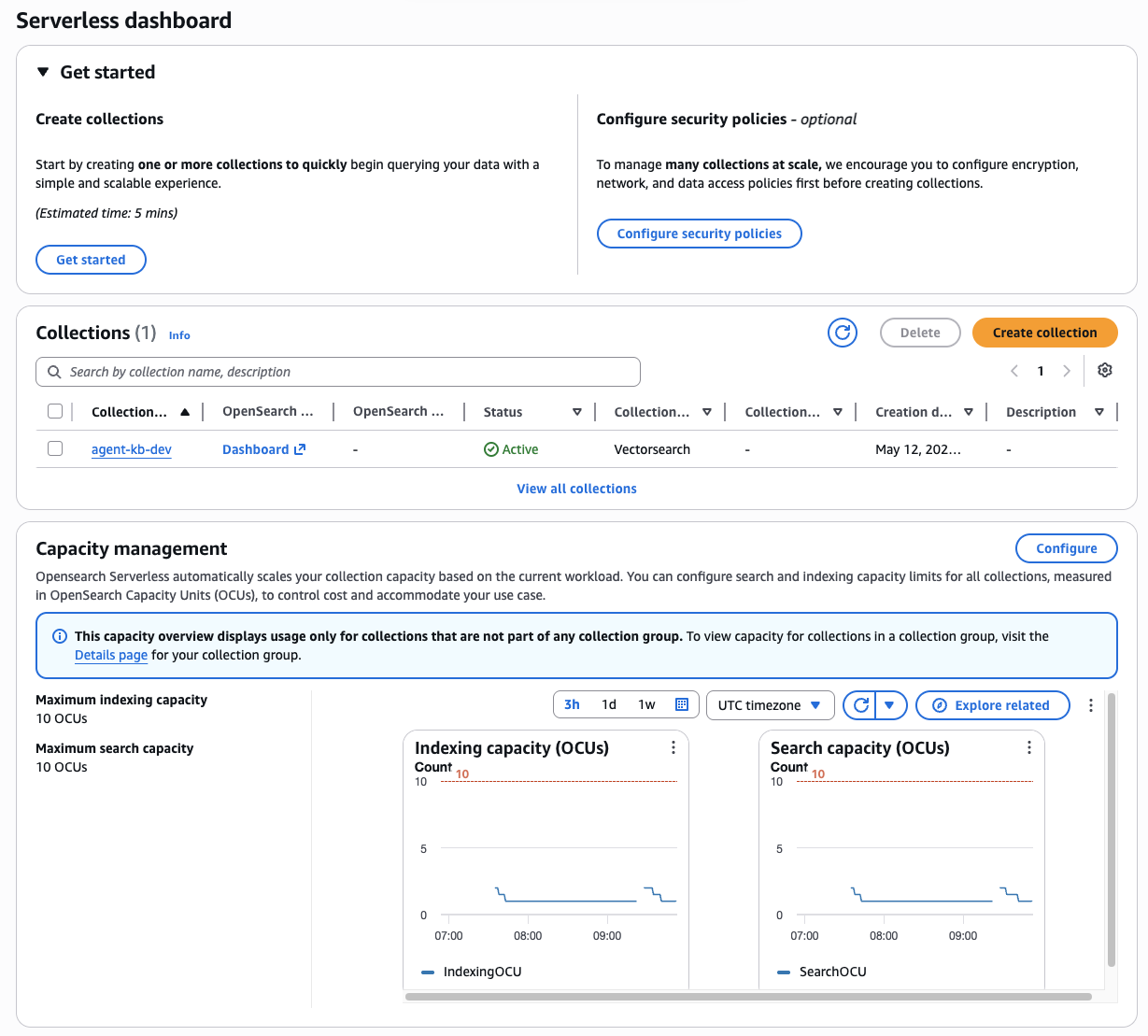
Figure 8 — OpenSearch Serverless dashboard: the agent-kb-dev collection (type: VectorSearch, status: Active). This collection is the vector store backing the Bedrock Knowledge Base. Indexing and search capacity scale automatically — no cluster sizing decisions, no idle cost during quiet periods beyond the minimum OCU baseline.
Memory Design Decision: Why Two Stores?
DynamoDB handles episodic memory — what was said in this conversation. It has sub-millisecond read latency and automatic TTL expiry, ideal for the recency-biased short-term context window. Bedrock KB handles semantic memory — what the agent has learned across all conversations. It provides vector similarity search across potentially millions of documents. Using a single store for both would force trade-offs on either latency or corpus size.
6. Reasoning Engine — ReAct Loop with Bedrock
This is the heart of the agent. Rather than a single LLM call, the Reasoning Engine implements the ReAct pattern (Reasoning + Acting): the model thinks, optionally calls a tool, observes the result, thinks again — until it reaches a final answer. The entire loop uses the Bedrock Converse API, which abstracts over all supported models. Swapping Claude for Titan or Llama requires changing a single environment variable.
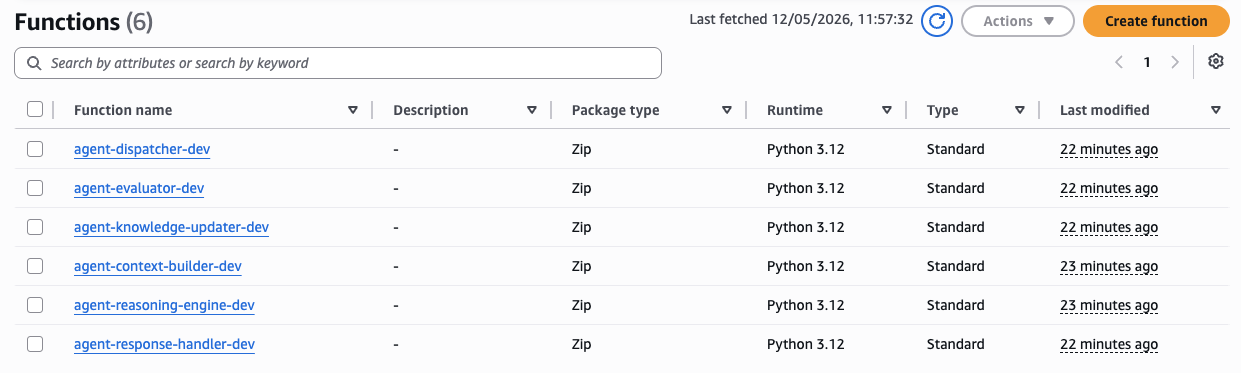
Figure 9 — AWS Lambda Console: all 6 agent functions deployed from a single agent_core.py archive via the lambda Terraform module. Each function has a dedicated handler (agent_core.dispatcher_handler, agent_core.reasoning_engine_handler, etc.), Python 3.12 runtime, and its own CloudWatch log group with 14-day retention. The Reasoning Engine uses a 120s timeout and 1024 MB memory; all others use 60s / 512 MB.
Why ReAct Instead of Fine-Tuning?
Fine-tuning teaches the model to behave differently by adjusting weights. ReAct teaches the model to reason differently through prompting. The difference matters at every stage of a product lifecycle:
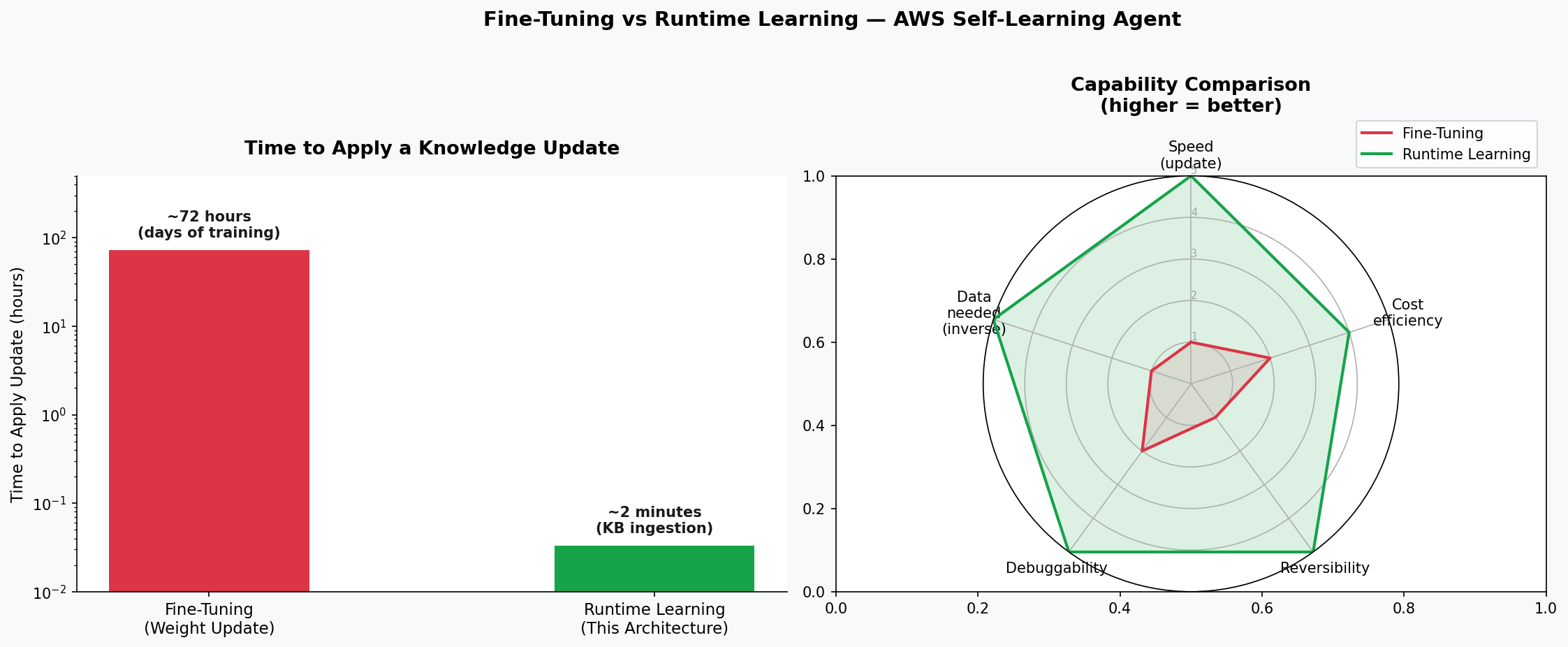
Figure 10 — Left: time to apply a knowledge update on a logarithmic scale. Fine-tuning takes ~72 hours; runtime learning (Bedrock KB ingestion) takes ~2 minutes — a 2,160× speedup. Right: radar chart comparing 5 capability dimensions. Runtime learning wins on speed, reversibility, debuggability, and data requirements; fine-tuning has a slight edge on cost efficiency only at very large scale.
| Dimension | Fine-Tuning | ReAct Prompting |
|---|---|---|
| Iteration speed | Days / weeks | Minutes |
| Cost per update | $$$ | $ per token |
| Debugging | Black box | Readable reasoning trace |
| Rollback | Re-train or revert model | Edit system prompt |
| Tool use | Requires specific training | Native Converse API feature |
The ReAct Loop Implementation
def _react_loop(messages: list[dict], max_iterations: int = 5):
for _ in range(max_iterations):
response = bedrock_rt.converse(
modelId=MODEL_ID,
system=[{"text": SYSTEM_PROMPT}],
messages=messages,
toolConfig={"tools": TOOL_DEFINITIONS},
inferenceConfig={"maxTokens": 2048, "temperature": 0.3},
)
stop_reason = response["stopReason"]
output_message = response["output"]["message"]
messages.append(output_message)
if stop_reason == "end_turn":
text = _extract_text(output_message)
learnings = _extract_learnings(text) # parse [LEARNING]: tags
return text, learnings, tool_calls_log
if stop_reason == "tool_use":
# Execute tool, append result, continue loop
tool_results = _execute_tools(output_message)
messages.append({"role": "user", "content": tool_results})The Learning Signal — [LEARNING]: Convention
The system prompt instructs the model to annotate newly discovered knowledge with a special tag:
SYSTEM: ...When you learn something new or receive a correction,
annotate it explicitly as [LEARNING]: <what was learned>
so the system can update its knowledge base.For example, if a user corrects the agent ("Our API rate limit was increased to 500 req/s last month"), the model will emit:
The current rate limit for your internal API is 100 req/s based on my knowledge.
[LEARNING]: The API rate limit was increased to 500 requests/second as of April 2026.The _extract_learnings() function parses these tags and passes the list downstream. The response_handler strips them from the user-facing output before returning the clean answer. The knowledge_updater writes them to S3 and triggers a Bedrock KB ingestion job. The next invocation of KB retrieval will include this new content — the agent has demonstrably learned.
7. Feedback Loop — Evaluator & Knowledge Updater
The learning loop closes in two Lambda functions that work in tandem: the Evaluator scores response quality, and the Knowledge Updater writes confirmed learnings back to the Knowledge Base.
Evaluator — LLM-as-Judge
The Evaluator uses Bedrock itself as a zero-shot quality judge — no labelled evaluation data required:
def _llm_judge(query: str, response: str) -> float:
prompt = f"""Rate the following AI assistant response on a scale from 0.0 to 1.0.
Criteria: accuracy, relevance, helpfulness, conciseness.
User query: {query}
AI response: {response}
Reply with ONLY a decimal number between 0.0 and 1.0. Nothing else."""
text = _invoke_bedrock(prompt, max_tokens=5)
return round(float(text.strip()), 3)Human feedback signals (thumbs-up/down from the /feedback API endpoint) are merged with the auto-score and written back to DynamoDB. An EventBridge rule fires nightly at 02:00 UTC to batch-evaluate responses with low confidence scores, flagging them for human review.
Knowledge Updater — Closing the Loop
When a turn produces learnings, the Knowledge Updater performs three actions:
- Write to S3 — serialise the learning list as a Markdown document in the KB source bucket, keyed by
learnings/{session_id}/{uuid}.md - Trigger ingestion — call
StartIngestionJobon the Bedrock Knowledge Base; Bedrock chunks, embeds, and indexes the new document asynchronously in OpenSearch Serverless - Archive interaction — write the full interaction JSON to the S3 history bucket with lifecycle rules to Glacier after 90 days
def _ingest_learnings(session_id: str, learnings: list[str]) -> None:
doc_key = f"learnings/{session_id}/{uuid.uuid4()}.md"
doc_body = f"# Agent Learnings — Session {session_id}\n\n"
doc_body += "\n".join(f"- {l}" for l in learnings)
s3.put_object(Bucket=kb_bucket, Key=doc_key, Body=doc_body.encode())
# Bedrock embeds + indexes asynchronously — no polling needed
bedrock_agent_mgmt.start_ingestion_job(
knowledgeBaseId=KB_ID,
dataSourceId=os.environ["KB_DATA_SOURCE_ID"],
)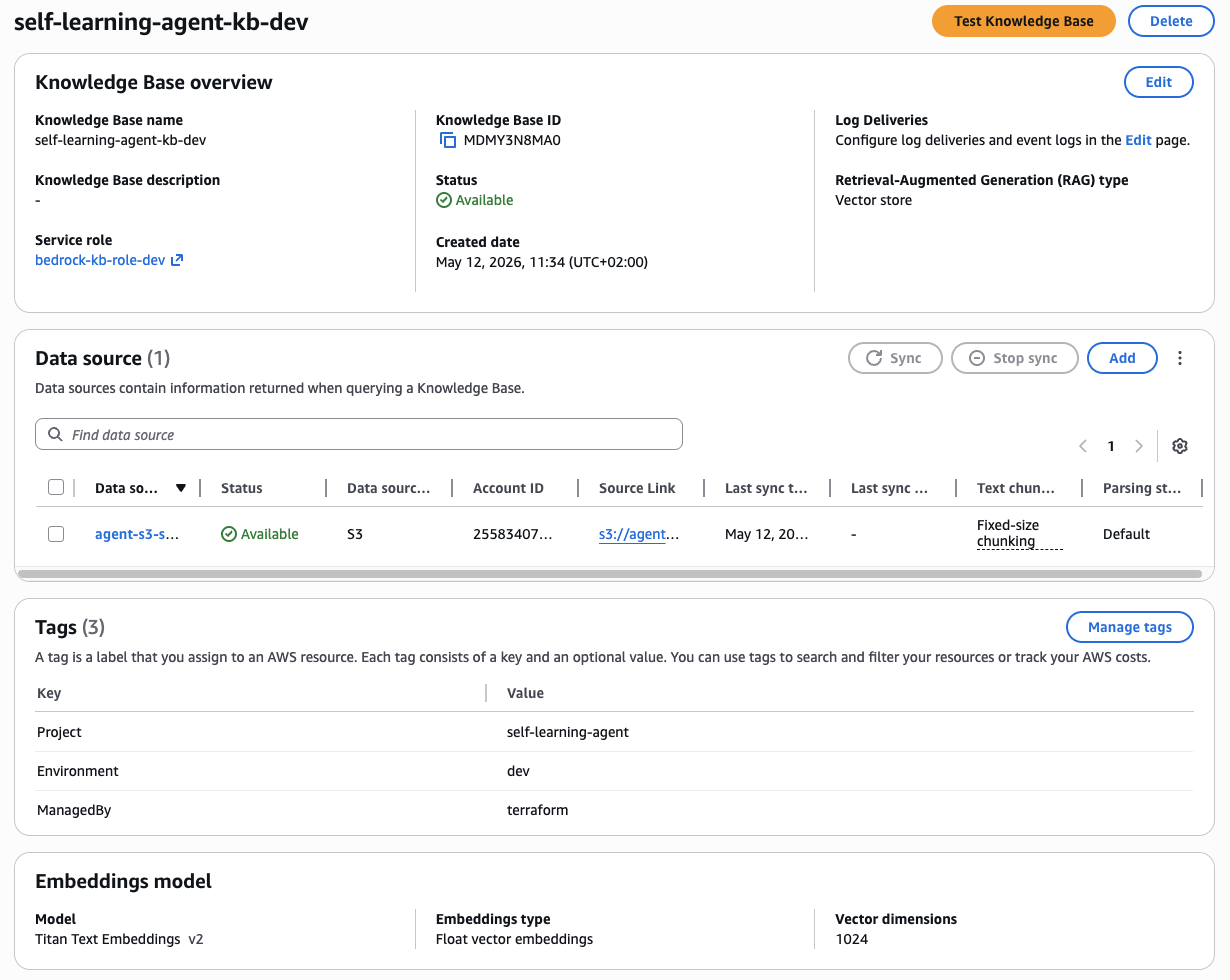
Figure 12 — Amazon Bedrock Knowledge Base self-learning-agent-kb-dev (ID: M0MY3N8MA0): status Available, embedding model Titan Text Embeddings v2 (1024 vector dimensions), S3 data source with Fixed-size chunking (512 tokens, 20% overlap). Every StartIngestionJob call processes new Markdown files from agent-kb-source-dev and updates the OpenSearch Serverless index, making the learning available to the next retrieval call within ~2 minutes.

Figure 13 — A real interaction document stored in agent-history-dev by the Knowledge Updater Lambda. The JSON shows: semantic_memory retrieved from Bedrock KB (AWS Lambda, Step Functions, DynamoDB, and Amazon Bedrock content chunks), tool_calls_log, and "has_learnings": true — confirming the pipeline detected a new learning signal in this session and triggered the KB ingestion job.
Production Constraint: One Concurrent Ingestion Job per KB
Bedrock Knowledge Bases allow only one active StartIngestionJob at a time per Knowledge Base. In high-volume systems, back-to-back learning events can cause ConflictException. The solution is to batch learnings into a single job: collect them in DynamoDB with a 30-second window, then flush with a single ingestion call rather than one per conversation turn.
8. Modular Terraform Infrastructure
The entire stack is provisioned with terraform apply. The configuration follows the same five-layer structure as the architecture — each module is independently testable and reusable.
terraform/
├── main.tf # Root module — wires all modules together
├── variables.tf # Configurable parameters
├── outputs.tf # API endpoint, state machine ARN, KB ID
└── modules/
├── storage/ # DynamoDB + S3 (history + KB source) + SQS
├── iam/ # Lambda role, SFN role, EventBridge role
├── bedrock/ # Knowledge Base + OpenSearch Serverless + Data Source
├── lambda/ # All 6 Lambda functions (agent_core.py lives here)
├── stepfunctions/ # Workflow state machine definition
├── eventbridge/ # Nightly evaluator + weekly KB check rules
└── apigw/ # REST API (/chat + /feedback) → Dispatcher LambdaKey Design Decisions
Module Dependency Graph
The modules are wired in strict dependency order to avoid circular references: storage and bedrock first (no dependencies), then iam (needs ARNs from storage), then lambda (needs role ARN + all service names), then stepfunctions (needs Lambda ARNs), then eventbridge and apigw last (need Lambda ARNs).
Reasoning Engine Lambda: 120s Timeout, 1024 MB
The multi-step ReAct loop can span up to 5 Bedrock calls. Default Lambda timeout (3s) would cause immediate failures. The increased memory allocation (1024 MB vs 512 MB default) also improves CPU allocation for JSON marshaling, which reduces total execution time by roughly 20% at this workload profile.
DynamoDB: PAY_PER_REQUEST + TTL
Episodic memory access is bursty — high during active conversations, near-zero otherwise. On-demand billing fits this pattern significantly better than provisioned throughput. The ttl attribute auto-expires records after one hour, keeping the table small without any maintenance Lambda.
OpenSearch Serverless for Knowledge Base
Bedrock Knowledge Bases require OpenSearch Serverless as the vector store. Unlike the managed OpenSearch Service, Serverless requires no cluster sizing decisions — it scales automatically with ingestion and query load, and idles to its minimum cost when inactive.
Deploy
# 1. Enable Bedrock model access first (one-time, in AWS Console):
# Console → Amazon Bedrock → Model access → Enable Claude 3.5 Sonnet + Titan Embeddings v2
cd terraform
terraform init
terraform plan -var="environment=dev"
terraform apply -var="environment=dev" -auto-approve
# Outputs after apply:
# api_endpoint = "https://xxxx.execute-api.us-east-1.amazonaws.com/dev/chat"
# knowledge_base_id = "XXXXXXXXXX"
# memory_table_name = "agent-episodic-memory-dev"9. Testing the Agent
The easiest way to verify the self-learning loop is working is a three-step test: ask a question, inject a correction, then ask the same question in a new session.
Step 1 — Baseline Query
curl -X POST https://xxxx.execute-api.us-east-1.amazonaws.com/dev/chat \
-H "Content-Type: application/json" \
-d '{
"session_id": "test-001",
"message": "What is the rate limit of our internal API?"
}'
# → "Based on my knowledge, the rate limit is 100 req/s."Step 2 — Inject a Learning
curl -X POST .../chat \
-d '{
"session_id": "test-001",
"message": "Update: the rate limit was increased to 500 req/s last month."
}'
# Model emits [LEARNING]: The API rate limit is 500 req/s as of April 2026.
# → Knowledge Updater writes to S3 → StartIngestionJob → KB indexed (~2 min)Step 3 — Verify Learning Persisted (New Session)
curl -X POST .../chat \
-d '{
"session_id": "test-002",
"message": "What is the rate limit of our internal API?"
}'
# → "The rate limit is 500 req/s as of April 2026."
# ✅ Agent learned — no fine-tuning, no redeploymentThe session ID change in Step 3 is the critical proof point: test-002 has no short-term memory of the previous conversation. The correct answer comes entirely from the updated Knowledge Base — the learning persisted across sessions.
10. Cost & Observability
Cost Estimate (Dev Workload — 1,000 Interactions/Day)
Assuming ~1,000 interactions/day with an average of 4 Bedrock calls per interaction (typical for a 2-step ReAct loop with KB retrieval):
| Service | Usage | Est. Cost/Month |
|---|---|---|
| Amazon Bedrock (Claude 3.5 Sonnet) | ~4M input + 2M output tokens | ~$30 |
| Lambda (6 functions) | ~4,000 invocations/day | ~$2 |
| DynamoDB (on-demand) | ~8,000 RW/day | ~$1 |
| S3 (history + KB source) | ~1 GB/month | ~$1 |
| OpenSearch Serverless | 0.5 OCU minimum | ~$70 |
| Step Functions | ~1,000 state transitions/day | ~$2 |
| Total | ~$106/month |
OpenSearch Serverless Dominates Cost
The ~$70/month OpenSearch Serverless minimum (0.5 OCU) is the largest cost component at dev scale. For low-traffic use cases, consider replacing it with Aurora Serverless v2 + pgvector as the Knowledge Base vector store, which runs at ~$30/month for small workloads. The Bedrock KB configuration supports multiple vector store types — the switch is a Terraform variable change, not an application code change.
Observability — What to Monitor
All Lambda functions write structured logs to CloudWatch. The key metrics to alert on:
| Metric | Source | Alert On |
|---|---|---|
reasoning_engine duration | Lambda metrics | p95 > 30s |
| Bedrock token usage | Bedrock CloudWatch | > 80% quota |
| KB ingestion job failures | CloudWatch Logs | Any ERROR |
| Low-confidence responses | DynamoDB scan | quality_score < 0.4 |
| DLQ message count | SQS metrics | > 0 |
| Step Functions execution failures | SFN metrics | Any ExecutionsFailed |
The most important metric is the ratio of [LEARNING]: extractions to total interactions — this is your agent's learning rate. If it drops to near zero, either the system prompt convention broke or users stopped providing new information. If it spikes unexpectedly, the model may be hallucinating learnings from ambiguous inputs.
11. Conclusion
The architecture demonstrates three principles that generalise beyond this specific project:
Separate memory from model weights. The LLM is stateless. All state — episodic turns, semantic knowledge, quality scores — lives in managed AWS data stores. This makes the "learning" durable, inspectable, and reversible. You can delete a bad learning by removing its S3 document and re-ingesting.
Use prompting as the primary adaptation mechanism. The ReAct loop, the [LEARNING]: extraction convention, and the LLM-as-judge evaluator are all prompt-level constructs. You can iterate on any of them in minutes without touching infrastructure. The Step Functions definition is the only place where "what happens when" is encoded — and it's a JSON document, not application code.
Let Step Functions own the control flow. A durable state machine separates what to do (orchestration) from how to do it (Lambda business logic). When the pipeline gains a new step — say, a web-search tool or a safety evaluation Lambda — you add it to the state machine definition without modifying existing functions.
The result is an agent that improves continuously from user interactions, costs a fraction of a fine-tuned model to operate, and can be deployed to production in an afternoon.
Full Source Code
Complete modular Terraform (7 modules) + Python Lambda handlers (6 modules in agent_core.py) — all in one repository.
Key Takeaways
- The
[LEARNING]:system prompt convention is the core mechanism — one annotation pattern turns any LLM response into a training signal without labels or GPUs. - Two memory types serve different purposes: DynamoDB handles per-session recency (sub-millisecond, auto-expiry), Bedrock KB handles cross-session semantics (vector similarity, unlimited scale).
- The
HasLearningsChoice state in Step Functions ensures knowledge ingestion only runs when needed — critical for keeping p50 latency low on routine queries. - The Bedrock Converse API with
toolConfigenables multi-step ReAct loops with any supported model, swappable via a single environment variable. - OpenSearch Serverless (~$70/month minimum) dominates cost at dev scale — evaluate Aurora + pgvector for low-traffic deployments.
- Monitor the learning rate (ratio of extractions to interactions) as a first-class metric — it is the health signal for the self-improvement loop.
