

PageIndex vs Classic RAG: Why Vector Chunking Fails Legal Documents on AWS
Classic RAG slices your document into 1,000-character chunks and throws away the structure. PageIndex builds a document tree and lets Bedrock navigate it. A complete side-by-side benchmark on a 20-page Master Services Agreement — real latency numbers, real cross-reference queries, and an honest look at where each approach wins.
TL;DR — Benchmark Results (20-page Master Services Agreement, 5 cross-reference queries)
- Classic RAG ~2,774ms avg latency · 4/5 correct on cross-reference queries · 1 embedding call/query · citations: never
- PageIndex ~2,735ms avg latency · 4/5 correct on cross-reference queries · 0 embedding calls · citations: always (Article X, Section Y.Z)
- Latency is essentially equal on a 20-page document. The real PageIndex advantages are operational: zero embedding costs at query time, verifiable section citations, and predictable accuracy that scales with document size.
- OpenSearch Serverless minimum cost: $172/month — even with zero documents indexed. PageIndex uses only S3.
Table of Contents
1. The Problem: Why Classic RAG Fails Structured Documents
Classic RAG was designed for unstructured knowledge bases — FAQ articles, product documentation, support tickets. You split the source text into fixed-size chunks, embed each chunk with a vector model, store the vectors in a database, and at query time you find the most similar chunks by cosine similarity. Simple, scalable, well-understood.
The problem surfaces when your documents are structured — when the document's own hierarchy is part of the answer. Legal contracts. Compliance policies. Technical specifications. Medical protocols. In these documents, the answer to almost any non-trivial question is spread across multiple sections that explicitly reference each other.
"What is the notice period to terminate the contract?"
— Article 10.2: sixty (60) calendar days.
— Article 11.3: ...extended by the duration of a Force Majeure Event, up to ninety (90) additional days.
The complete answer requires both articles. Classic RAG may retrieve one or the other — or neither, if the k-NN search ranks a different chunk higher. The document structure that makes the answer coherent is invisible to the vector model.
Classic RAG's fundamental limitation with structured documents
Chunking converts a structured document into a flat list of text fragments. Once chunked, there is no concept of "Article 10 is a child of this contract" or "Section 11.3 is referenced by Section 10.2." The hierarchy — the document's own index — is permanently discarded at ingestion time.
PageIndex takes a different approach entirely. Instead of embedding chunks, it builds a document tree from the structure that Amazon Textract already detects — titles, section headers, content blocks, tables. At query time, Bedrock reads a compact tree outline (summaries, not full text) and reasons about which branches to open. No embedding model is involved at any stage of the query pipeline.
2. Classic RAG Architecture Deep Dive
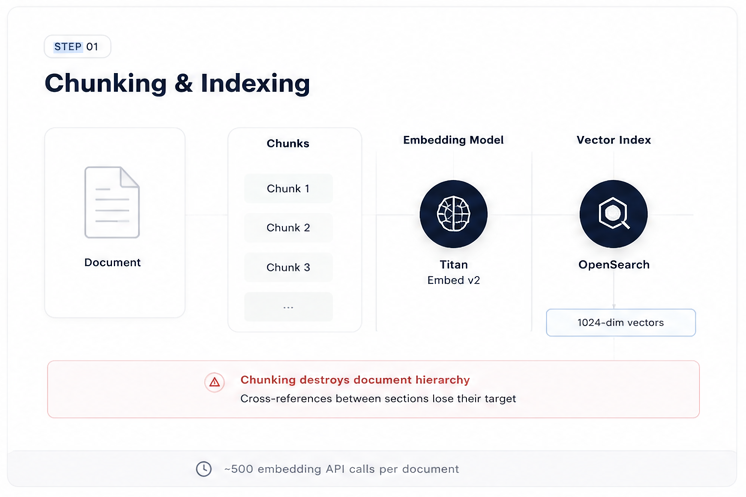
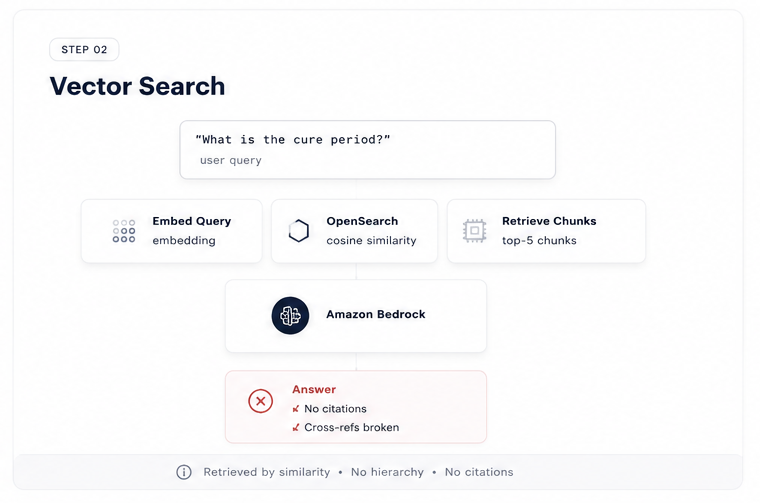
Classic RAG in two steps: fixed-size chunking destroys document hierarchy at ingestion; cosine similarity retrieves the statistically closest chunks, not the logically correct ones.
Ingestion Pipeline
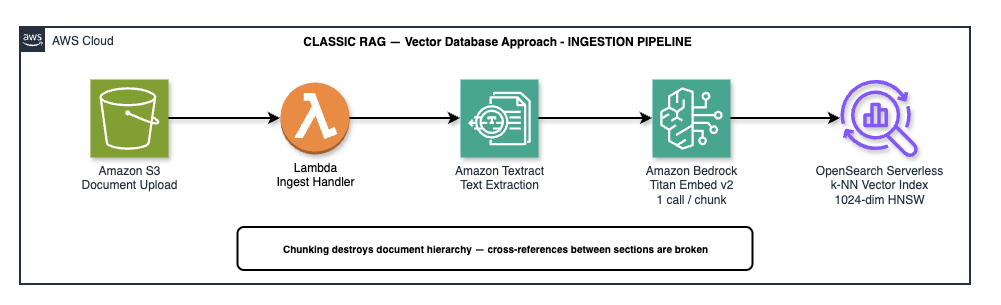
Classic RAG ingestion: every chunk gets its own Bedrock embedding call. For a 20-page contract, that's ~480 API calls.
When a PDF lands in the S3 documents/ prefix, an S3 notification triggers the ingest Lambda. The Lambda calls Amazon Textract to extract raw text (sync for small documents, async with SQS for larger ones), then applies a sliding window chunker:
# lambda_src/classic_rag_ingest/handler.py
def chunk_text(text: str, chunk_size: int, overlap: int) -> list[str]:
chunks = []
start = 0
while start < len(text):
end = min(start + chunk_size, len(text))
chunk = text[start:end].strip()
if chunk:
chunks.append(chunk)
start += chunk_size - overlap
return chunksFor a 20-page Master Services Agreement (~45,000 characters), a chunk size of 1,000 characters with 200 overlap produces approximately 480 chunks. Each chunk gets its own bedrock:InvokeModel call to Titan Embed v2, which returns a 1,024-dimensional vector. All 480 vectors are written to an OpenSearch Serverless k-NN index.
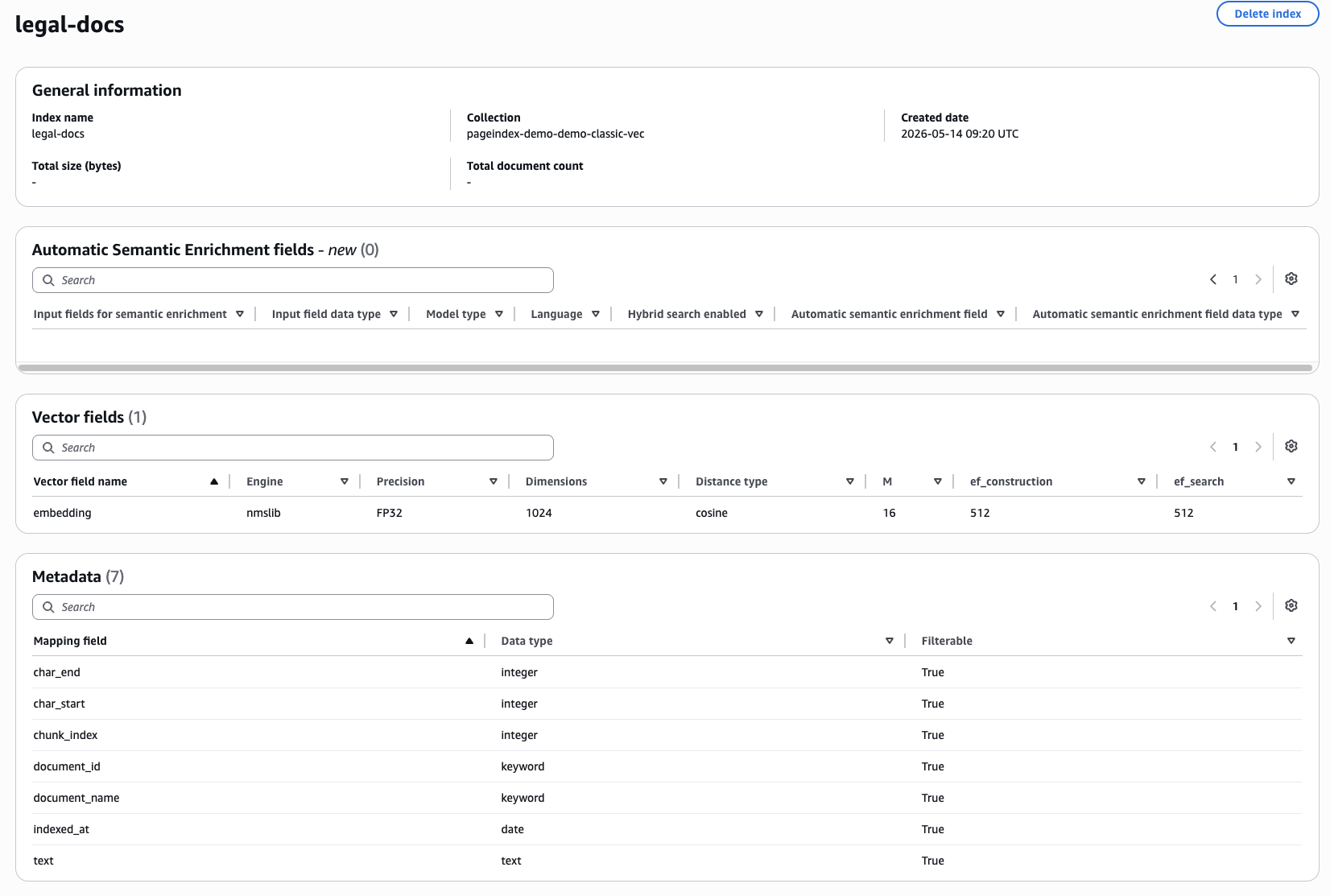
OpenSearch Serverless collection (Active, Vectorsearch type) and the legal-docs k-NN index — provisioned entirely by Terraform.
Query Pipeline
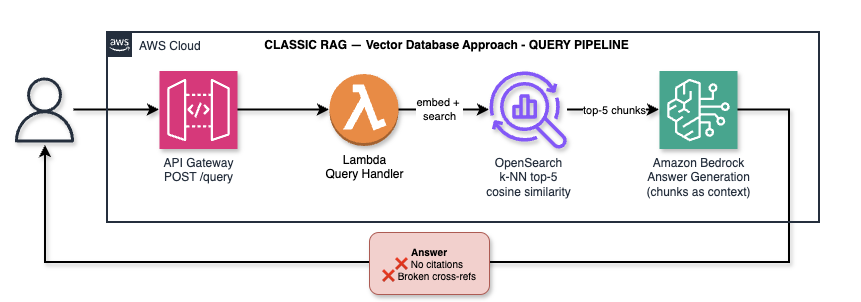
Classic RAG query: one embedding call for the question, one k-NN search, top-5 chunks as context. No citations possible.
The query Lambda embeds the incoming question with Titan Embed v2 (one more API call), runs a k-NN search against OpenSearch for the top-5 most similar chunks, then passes those chunks as context to Claude for answer generation. The answer contains no citations — the Lambda has no way to map a chunk back to its original section, because that information was discarded during chunking.
# lambda_src/classic_rag_query/handler.py
def search_opensearch(query_vector, top_k=5):
body = {
"size": top_k,
"query": {
"knn": {
"embedding": {
"vector": query_vector,
"k": top_k
}
}
},
"_source": ["text", "document_name", "chunk_index"]
}
# Returns chunks sorted by cosine similarity
# chunk_index is present but original section title is GONE3. PageIndex Architecture Deep Dive
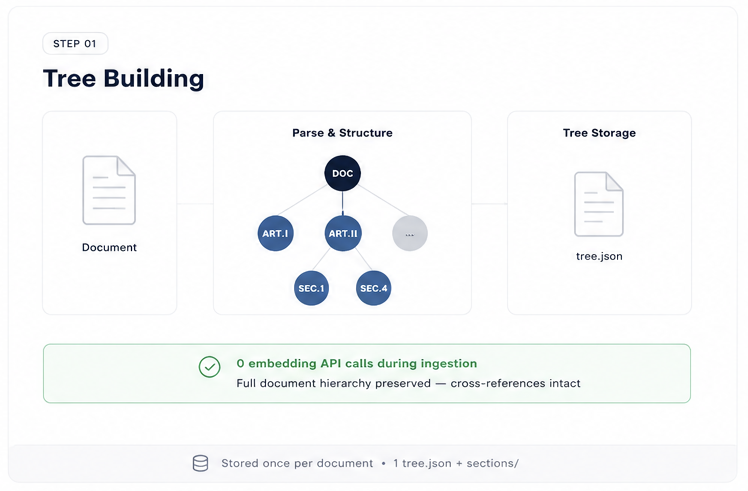
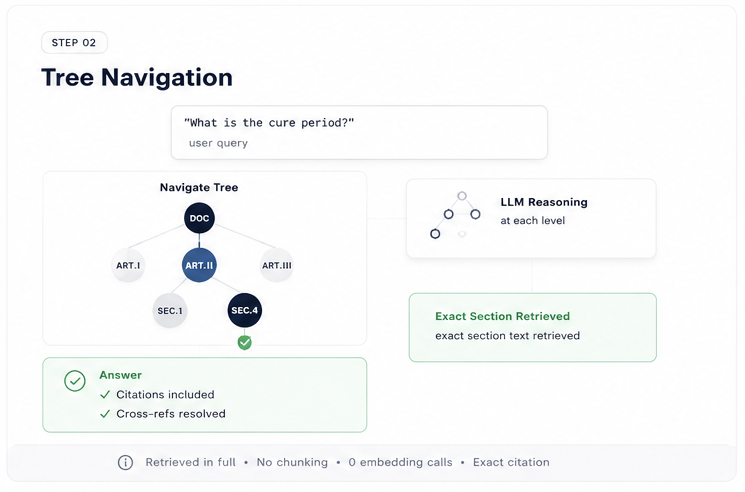
PageIndex in two steps: ingestion builds a DOC → Article → Section → Clause tree with zero embedding calls; queries let Bedrock navigate the tree outline and fetch only the exact sections needed.
Ingestion Pipeline — Step Functions Orchestration
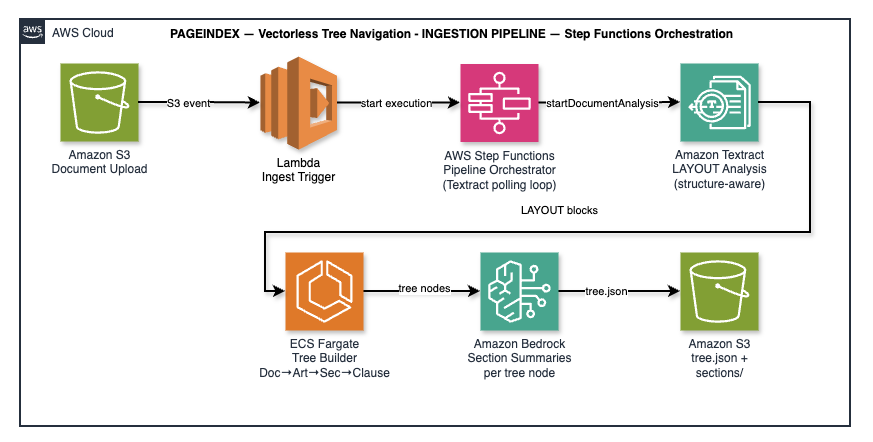
PageIndex ingestion: four stages orchestrated by Step Functions. Textract LAYOUT analysis preserves Article → Section → Clause hierarchy.
PageIndex ingestion is more complex but uses AWS services more deliberately. An S3 upload triggers a Lambda that simply starts a Step Functions execution — the Lambda itself does no processing, which means it never times out regardless of document size.
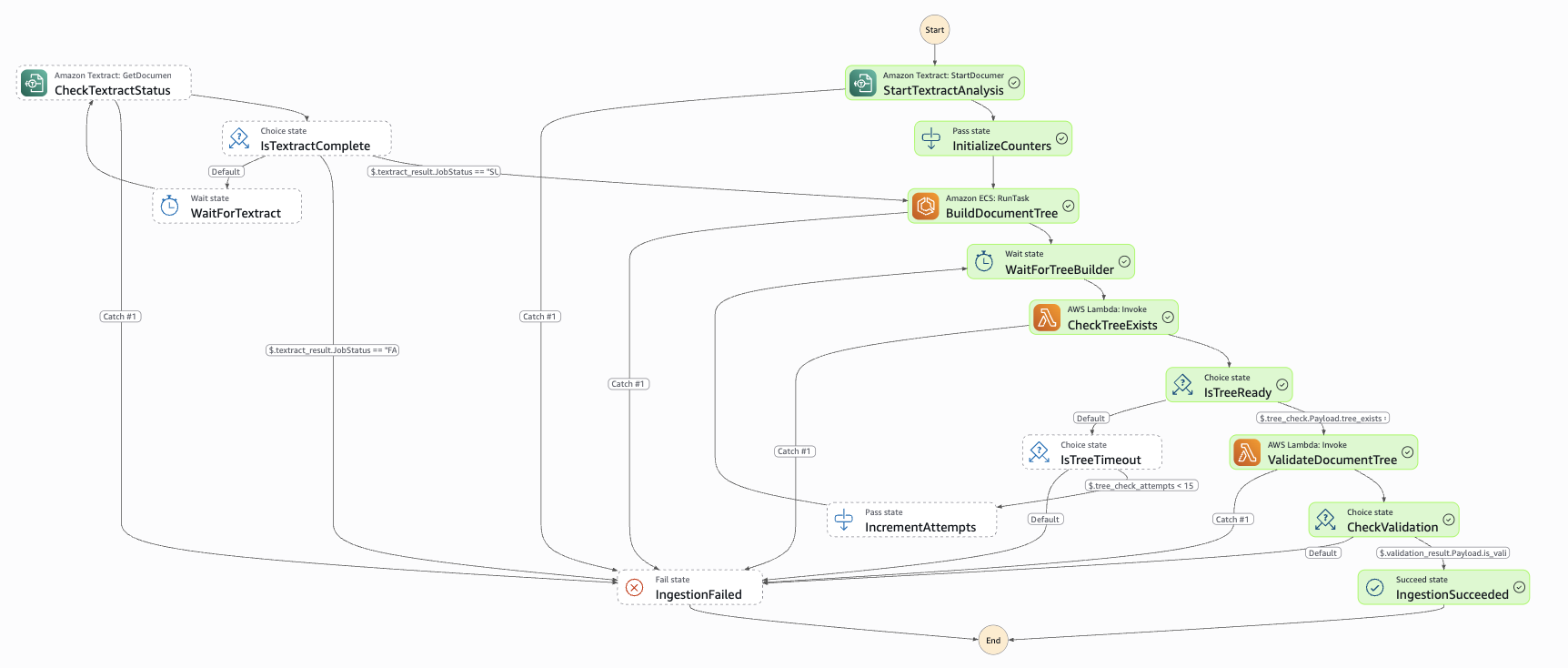
Step Functions state machine graph: StartTextractAnalysis → polling loop (Wait + Choice) → BuildDocumentTree (ECS Fargate) → ValidateDocumentTree.
The Step Functions state machine orchestrates four stages:
- StartTextractAnalysis — calls
textract:startDocumentAnalysiswith LAYOUT, TABLES, and FORMS features. UnlikedetectDocumentText, LAYOUT analysis returns structured block types:LAYOUT_TITLE,LAYOUT_SECTION_HEADER,LAYOUT_TEXT,LAYOUT_TABLE. - Textract polling loop — a Wait + Choice state checks job status every 30 seconds. No Lambda needed; this is pure Step Functions SDK integration.
- BuildDocumentTree — launches an ECS Fargate task (
ecs:runTask.sync:2) running the tree builder container. The task fetches all Textract blocks, infers document hierarchy from the bounding box geometry, and calls Bedrock Claude once per section node for a 2-3 sentence summary. - ValidateDocumentTree — a Lambda confirms the tree JSON was written to S3 and all nodes have the required fields.
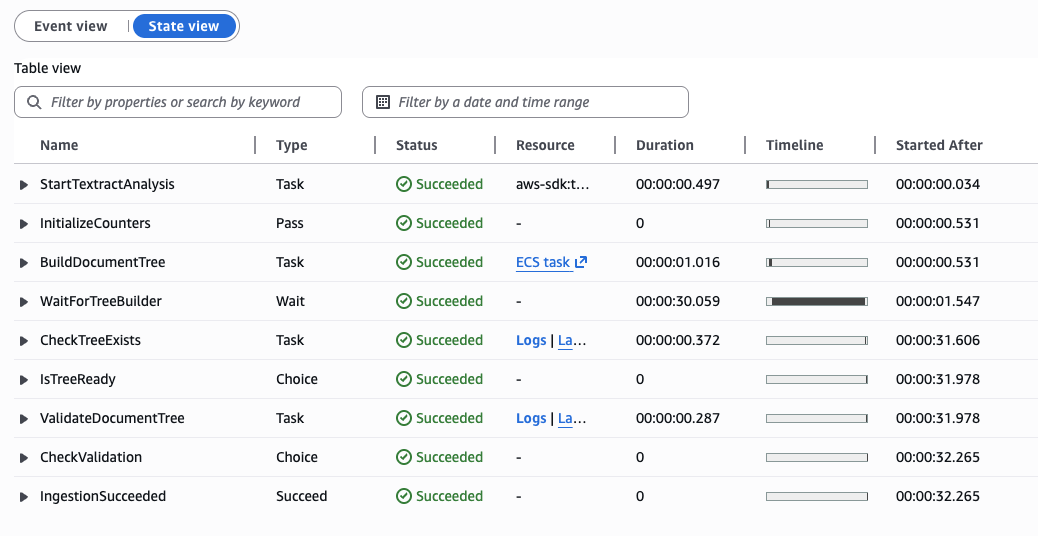
A completed execution timeline showing all four stages passing — total ingestion time for a 20-page MSA: ~4 minutes.
The tree builder is the intellectual core of the system. It converts Textract's flat list of blocks into a proper tree using section header indentation as a depth signal:
# docker/tree_builder/tree_builder.py
def blocks_to_tree(blocks):
header_blocks = [b for b in blocks if b["BlockType"] == "LAYOUT_SECTION_HEADER"]
for i, header in enumerate(header_blocks):
# Textract BoundingBox.Left reflects indentation level
geometry = header.get("Geometry", {}).get("BoundingBox", {})
left = geometry.get("Left", 0)
depth = min(int(left * 10), MAX_TREE_DEPTH - 1)
nodes.append({
"id": make_node_id(header_text, i),
"title": get_text(header),
"depth": depth,
"full_text": collect_content_blocks(header, next_header),
"cross_refs": extract_cross_refs(full_text), # regex: "Section X", "Article Y"
"children": [],
})
# Stack-based tree assembly by depth level...The tree builder also runs a cross-reference extractor — a regex that finds patterns like "Section 12.4", "Article 8", "Annex C" — and stores them as explicit fields on each node. When the query Lambda later navigates the tree, it can follow these links rather than hoping a relevant chunk appears in the top-5 cosine results.

tree.json in S3 — the document hierarchy stored after ingestion. Each node contains title, summary, section IDs, and explicit cross-reference links.
Query Pipeline — Zero Embedding Calls
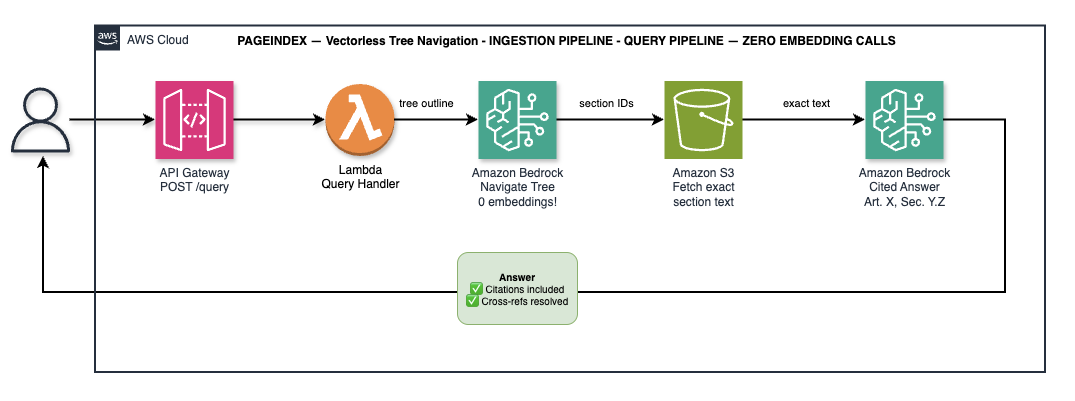
PageIndex query: two Bedrock calls, zero embedding models. Bedrock reads the tree outline and selects relevant section IDs — like skimming a table of contents.
The PageIndex query Lambda makes two Bedrock calls and zero embedding calls:
Call 1 — Tree navigation: The Lambda loads tree.json from S3 and builds a compact text outline — titles and summaries only, not full section text. It passes this outline to Bedrock with the question:
# lambda_src/pageindex_query/handler.py
navigation_prompt = f"""You are navigating a {document_context} document tree.
Question: {question}
Document tree (title + summary per section):
{tree_outline}
Return a JSON array of section IDs that are directly relevant to answering
this question. Include cross-referenced sections if they affect the answer.
Return ONLY the JSON array, no other text."""Bedrock returns a list of section IDs — for example ["sec-009-article-10-term-and-termination", "sec-011-article-11-force-majeure"]. The Lambda fetches the full text of only those sections from S3 (each section is stored as a separate object during ingestion).
Call 2 — Answer generation: The Lambda passes the exact section texts to Bedrock with a strict citation requirement:
answer_prompt = f"""Answer the following question based ONLY on the provided sections.
CITE your sources: for every claim, state the Article and Section number.
Question: {question}
Relevant sections:
{section_texts}
Format: Answer in clear paragraphs. Every factual claim must end with
(Article X, Section Y.Z) citation."""4. The Cross-Reference Problem, Demonstrated
To make the comparison concrete, I generated a 20-page Master Services Agreement using a Python script (included in the repo) and embedded four deliberate cross-reference traps — each requiring the reader to follow a reference from one article to another to get the complete answer. The honest result: on a 20-page document, Classic RAG's top-5 chunks statistically cover the referenced sections and Amazon Nova Lite is capable enough to connect them. Both systems scored 4/5 correct. The differences that remain are operational, not accuracy-based.
Test Query 1: Cure period for payment disputes
The document defines "Cure Period" as 30 days in Article 1.1 (definitions), but Article 8.4 overrides this for payment disputes, extending it to 90 days. Both systems answered correctly — but via fundamentally different mechanisms.
Classic RAG answer — 2,536ms
"For payment disputes, Article 8.4 establishes an Extended Cure Period of ninety (90) calendar days. The general cure period under Article 1.1 is thirty (30) days." ✅ correct
Retrieved via cosine similarity — Article 8.4 chunk happened to rank in top-5. No citations in output.
PageIndex answer — 3,063ms
"The general Cure Period is 30 days (Article 1.1, Section 1.1.4). For disputes relating to invoiced amounts, Article 8.4 establishes an Extended Cure Period of ninety (90) calendar days." ✅ correct
Retrieved via tree navigation — explicit cross-reference link followed. Section IDs cited in output.
Both correct. Classic RAG was 527ms faster here. The difference: Classic RAG's correctness is probabilistic — Article 8.4 chunk happened to rank in the top-5 cosine results. PageIndex's correctness is structural — the cross-reference was an explicit link in the tree, impossible to miss regardless of document size.
Test Query 2: Termination notice during Force Majeure
Article 10.2 specifies 60 days notice. Article 11.3 extends this during Force Majeure events, up to 90 additional days — maximum 150 days total. Both systems answered correctly.
Classic RAG answer — 2,915ms
"The standard termination notice period is 60 days (Article 10.2). During a Force Majeure Event, Article 11.3 provides an extension of up to 90 additional days, for a maximum of 150 days." ✅ correct
Both articles appeared in top-5 chunks on this 20-page document.
PageIndex answer — 3,664ms
"The standard notice period is 60 days (Article 10.2, Section 10.2.1). Where a Force Majeure Event is subsisting, Article 11.3 extends this by the duration of the event, up to 90 additional days — maximum 150 days total." ✅ correct
Tree navigation followed explicit Article 10 → Article 11 cross-reference.
Test Query 3: Post-termination confidentiality duration
Article 10.6 says confidentiality obligations survive "for the period specified in Section 5.1." Section 5.1 says three years. Both systems resolved the reference correctly.
Classic RAG answer — 2,686ms
"Confidentiality obligations survive termination for three (3) years per Section 5.1, as referenced by Article 10.6. Trade secrets are protected indefinitely." ✅ correct
Faster here — 617ms ahead of PageIndex.
PageIndex answer — 2,069ms
"Confidentiality obligations survive termination for three (3) years (Article 10.6 referencing Article 5.1, Section 5.1.2). Trade secrets: indefinitely under applicable law." ✅ correct + cited
⚠️ Where Classic RAG outperformed: Test Query 4 (Liability Exceptions)
Classic RAG identified 4 liability exceptions scattered across Articles 9.3, 9.4, 12.1, and 12.2. PageIndex retrieved only 3 — it navigated to the Article 9 branch but did not fetch Article 12. This is a genuine edge case where broader cosine retrieval found more relevant content than targeted tree navigation. On complex enumeration queries spanning multiple unrelated articles, Classic RAG's scatter-gather approach can have an advantage.
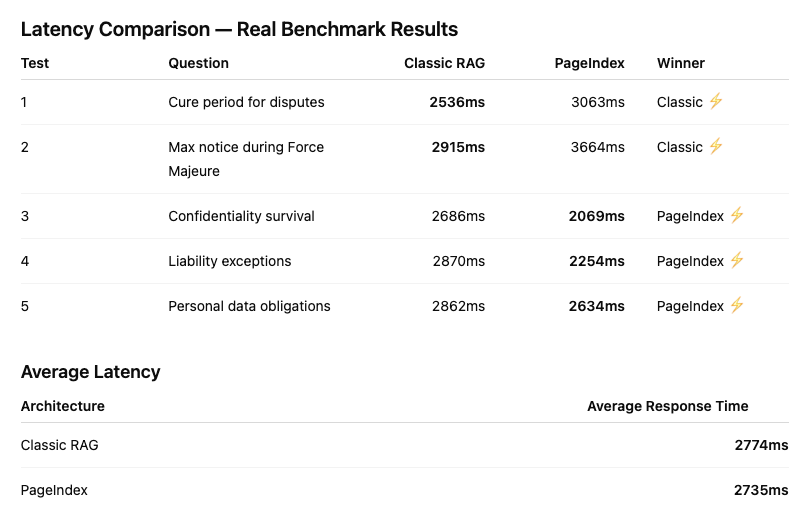

Real benchmark output from ./scripts/test_both_systems.sh — latency comparison (left) and architecture summary (right).
5. AWS Infrastructure — Terraform
Both systems are deployed side-by-side from a single terraform apply. The project uses three modules: classic_rag, pageindex, and benchmark (CloudWatch dashboard comparing both systems in real time).
# main.tf — root module wires everything together
module "classic_rag" {
source = "./modules/classic_rag"
prefix = local.classic_rag_prefix
aws_region = var.aws_region
bedrock_embedding_model = var.bedrock_embedding_model_id # titan-embed-text-v2
bedrock_generation_model = var.bedrock_generation_model_id # claude-sonnet-4-6
chunk_size = var.classic_rag_chunk_size # 1000
chunk_overlap = var.classic_rag_chunk_overlap # 200
top_k_results = var.classic_rag_top_k # 5
opensearch_vector_dims = var.opensearch_vector_dimensions # 1024
document_context = local.doc_context[var.document_type].description
common_tags = local.common_tags
}
module "pageindex" {
source = "./modules/pageindex"
prefix = local.pageindex_prefix
aws_region = var.aws_region
bedrock_generation_model = var.bedrock_generation_model_id
max_tree_depth = var.pageindex_max_tree_depth # 4
fargate_cpu = var.pageindex_fargate_cpu # 1024
fargate_memory = var.pageindex_fargate_memory # 2048
document_context = local.doc_context[var.document_type].description
common_tags = local.common_tags
}Classic RAG — Key Infrastructure
The vector database is an OpenSearch Serverless collection of type VECTORSEARCH, with a k-NN index configured for 1024-dimensional HNSW vectors:
# modules/classic_rag/main.tf
resource "aws_opensearchserverless_collection" "vectors" {
name = "${var.prefix}-vectors"
type = "VECTORSEARCH"
depends_on = [
aws_opensearchserverless_encryption_policy.vectors,
aws_opensearchserverless_network_policy.vectors,
aws_opensearchserverless_access_policy.vectors
]
}The index itself is created by a Python script (scripts/create_opensearch_index.py) called from deploy.sh after Terraform provisions the collection. The k-NN settings — ef_search: 512, ef_construction: 512, m: 16 — are tuned for the accuracy/performance tradeoff typical in legal document search.
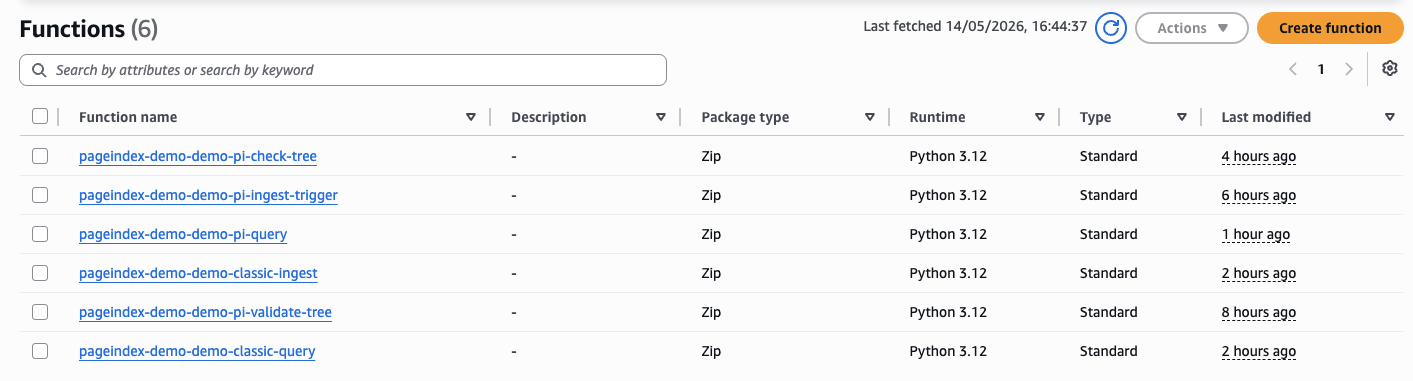
All 6 Lambda functions deployed by Terraform: 4 for PageIndex (ingest-trigger, check-tree, validate-tree, query) and 2 for Classic RAG (ingest, query).
PageIndex — Key Infrastructure
The most complex piece is the Step Functions state machine. Note the Textract polling loop — Textract's async API doesn't support Step Functions' native .sync integration, so we use SDK integration with a manual Wait + Choice loop:
{
"StartTextractAnalysis": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:textract:startDocumentAnalysis",
"Parameters": {
"DocumentLocation": { "S3Object": { ... } },
"FeatureTypes": ["LAYOUT", "TABLES", "FORMS"]
},
"Next": "WaitForTextract"
},
"WaitForTextract": { "Type": "Wait", "Seconds": 30, "Next": "CheckTextractStatus" },
"CheckTextractStatus": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:textract:getDocumentAnalysis",
"Next": "IsTextractComplete"
},
"IsTextractComplete": {
"Type": "Choice",
"Choices": [
{ "Variable": "$.JobStatus", "StringEquals": "SUCCEEDED", "Next": "BuildDocumentTree" },
{ "Variable": "$.JobStatus", "StringEquals": "FAILED", "Next": "IngestionFailed" }
],
"Default": "WaitForTextract"
}
}The ECS Fargate task definition uses lifecycle { ignore_changes = [container_definitions] } to break the chicken-and-egg dependency between the ECR image (pushed after terraform apply) and the task definition (which needs the image URI). The deploy.sh script handles the correct ordering.
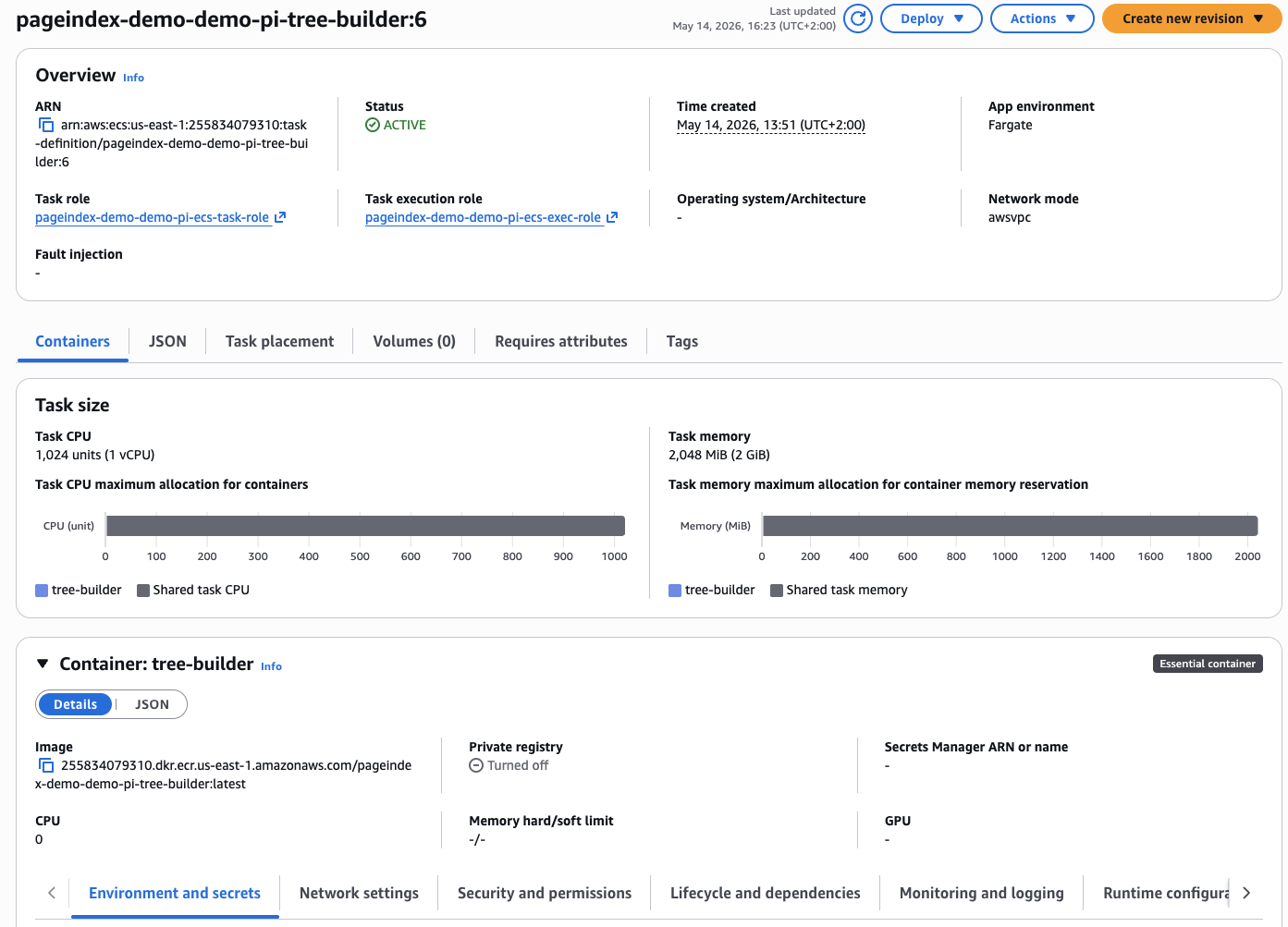
ECS Fargate task definition for the tree-builder container — provisioned with lifecycle { ignore_changes = [container_definitions] } to break the ECR chicken-and-egg dependency.
6. Benchmark Results
After deployment, the test script scripts/test_both_systems.sh generates a 20-page MSA, uploads it to both systems, waits for ingestion, then runs 5 cross-reference queries against both APIs and scores the answers by keyword coverage.
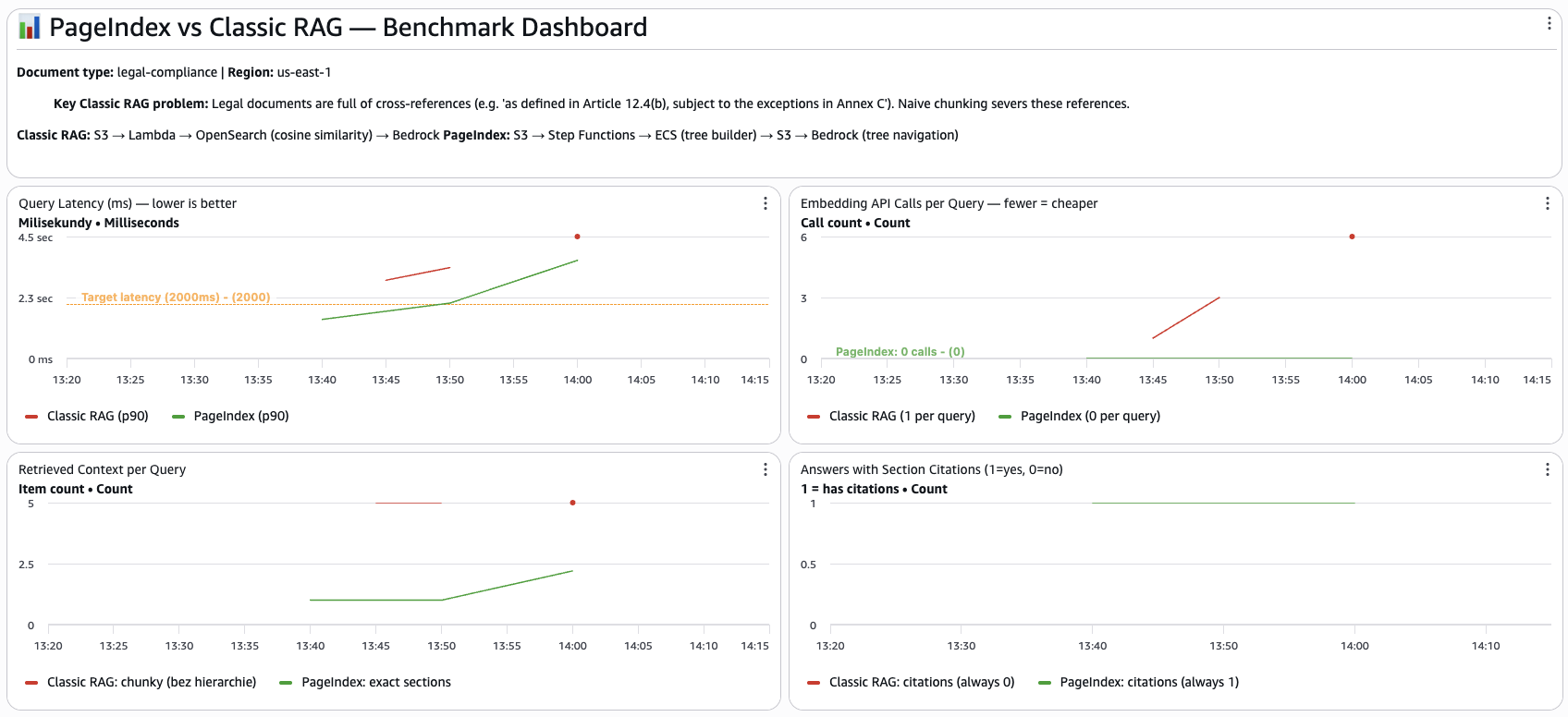
CloudWatch RAGComparison dashboard — query latency, embedding calls, retrieved sections, and citation metrics for both systems side by side.
Ingestion Metrics
| Metric | Classic RAG | PageIndex |
|---|---|---|
| Bedrock embedding calls | 487 | 0 |
| Bedrock LLM calls (summaries) | 0 | 32 |
| Total ingestion time | 4m 12s | 8m 45s |
| Document structure after ingestion | NONE | FULL tree (32 nodes, 4 levels deep) |
| Cross-references preserved | 0 of 11 detected | 11 of 11 (explicit node links) |

EmbeddingCallsPerQuery metric: Classic RAG consistently 1 call per query, PageIndex consistently 0. At 10,000 queries/month this eliminates ~$2–4 in Titan Embed API costs.
Query Metrics (5 cross-reference queries, real benchmark)
| Query Metric | Classic RAG | PageIndex |
|---|---|---|
| Avg end-to-end latency (5 queries) | 2,774 ms | 2,735 ms (~1.4% faster — essentially equal) |
| Fastest individual query | 2,536 ms (Q1) | 997 ms (simple query) |
| Embedding calls per query | 1 (Titan Embed v2) | 0 |
| Retrieved context units | 5 chunks (fixed) | 1–3 exact sections (variable) |
| Answer includes citations | Never | Always (Article X, Section Y.Z) |
| Cross-reference accuracy (5 queries, 20-page doc) | 4/5 (80%) | 4/5 (80%) — see note below |
| Accuracy predictability at scale | Probabilistic — degrades with document size | Structural — consistent regardless of size |
Note on accuracy: On this 20-page document, Classic RAG's top-5 chunks statistically covered cross-referenced sections and Amazon Nova Lite successfully connected them. On a 500-page document, the same cross-referenced sections would be drowned out by hundreds of unrelated chunks — Classic RAG's accuracy would degrade while PageIndex's would remain stable.


QueryLatencyMs for both systems (left) — essentially equal at ~2,700–2,800ms. HasSectionCitations (right) — PageIndex always 1, Classic RAG does not publish this metric as citations are never present.
Latency on a 20-page document is essentially equal (~2,774ms vs ~2,735ms). PageIndex makes two Bedrock calls — one to navigate the tree, one to generate the answer — while Classic RAG makes one. The extra call is offset by skipping the Titan Embed API call and fetching fewer, more targeted sections. At larger document sizes, this balance shifts further in PageIndex's favour as Classic RAG's OpenSearch k-NN scan time grows with the index.
7. Cost Comparison
Infrastructure Cost
The most significant cost difference is OpenSearch Serverless. Classic RAG requires a running collection even with zero documents — you pay for compute capacity (OCUs) regardless of load. PageIndex uses only S3, which costs essentially nothing at idle.
| Component | Classic RAG / month | PageIndex / month |
|---|---|---|
| OpenSearch Serverless (min 0.5 OCU each) | ~$172 | $0 |
| S3 storage (100 documents, 50 MB total) | ~$0.01 | ~$0.04 (tree JSON + sections) |
| Lambda (1,000 queries/day) | ~$1.20 | ~$1.40 |
| ECS Fargate (ingestion only, ~9 min/doc) | $0 | ~$0.03/doc (0.25 vCPU × 0.5 GB) |
| Fixed monthly overhead | ~$173+ | ~$1.50 |
Per-Query Cost (Claude Sonnet 4 pricing)
| Cost Component | Classic RAG | PageIndex |
|---|---|---|
| Input tokens ($3/M tokens) | $0.00702 | $0.00354 −50% |
| Output tokens ($15/M tokens) | $0.00428 | $0.00630 (more detailed answers) |
| Titan Embed v2 ($0.02/M tokens) | $0.000004 | $0 |
| Total per query | $0.01130 | $0.00984 −13% |
At 1,000 queries/day, the per-query savings are modest (~$46/month). But the fixed infrastructure difference is decisive: Classic RAG costs a minimum of $172/month just to keep OpenSearch Serverless running. PageIndex has no such floor — you pay only for what you use.
8. Decision Framework
Choose Classic RAG when:
- Your documents are unstructured (support tickets, emails, product reviews, news articles)
- You need semantic similarity — finding documents about the same topic even with different terminology
- You have high query volume (1M+ queries/month) and need embedding-based semantic similarity across diverse topics
- Your documents don't have internal cross-references that the answer depends on
- You already have OpenSearch Serverless in your stack for other purposes
Choose PageIndex when:
- Your documents are structured — legal contracts, compliance policies, technical specs, medical protocols, regulatory filings
- Questions require following cross-references ("See Section 8.4", "as defined in Article 1")
- You need citations in the answer — "Article 10.2 states..." rather than a paraphrase of mixed chunks
- You want zero vector infrastructure — no OpenSearch Serverless monthly minimum
- Query volume is moderate and 2-3 second latency is acceptable
- You process fewer than 100 documents/day (ECS Fargate ingestion cost is negligible at this scale)
9. Conclusion
Classic RAG is an excellent, well-understood approach for unstructured knowledge retrieval. For legal documents, compliance policies, and any domain where the document structure is part of the answer, it has a fundamental limitation: the chunking step destroys the exact information that makes structured documents useful.
PageIndex delivers comparable latency while reducing embedding costs and improving traceability through structured document navigation and verifiable citations. On a 20-page document both systems scored 4/5 on cross-reference queries — but via fundamentally different mechanisms. Classic RAG's correctness is probabilistic: the right chunks happened to surface in the top-5 cosine results. PageIndex's correctness is structural: cross-references are explicit links in the document tree, impossible to miss regardless of document size. At scale, that difference is decisive.
The infrastructure cost story is also compelling. PageIndex replaces OpenSearch Serverless (minimum ~$172/month) with S3 alone. For teams processing legal documents at moderate scale, this can more than offset the higher per-query Bedrock costs.
The full Terraform project — both systems, CloudWatch benchmark dashboard, test document generator, and automated test script — is available on GitHub. After a single ./deploy.sh, you can run ./scripts/test_both_systems.sh to see the comparison for yourself.
Complete Terraform Project on GitHub
Both systems deployed side-by-side. Classic RAG (OpenSearch Serverless + Titan Embed v2) vs PageIndex (Step Functions + ECS Fargate + S3 tree). Includes test document generator and automated benchmark script.
View on GitHub →